0. Preface
“Distributed Systems for Fun and Profit” is a booklet introducing distributed systems freely published online by mixu in 2013.
Two outcomes of distribution:
- Information travels at the speed of light
- Independent nodes fail independently
Distributed systems deal with the problems of distance and multiple nodes.
1. Distributed Systems at a High Level
Basic tasks of a computer:
- Storage
- Computation
Distributed programming is using multiple machines to solve the same problem as on a single machine, usually because the problem has outgrown the capacity of a single machine.
At a small scale, upgrading hardware on a single node can solve the problem, but as the scale increases, when single-node upgrades cannot solve the problem or become too expensive, distributed systems are needed. Currently, the most cost-effective approach uses mid-range commodity hardware, lowering costs through fault-tolerant software.
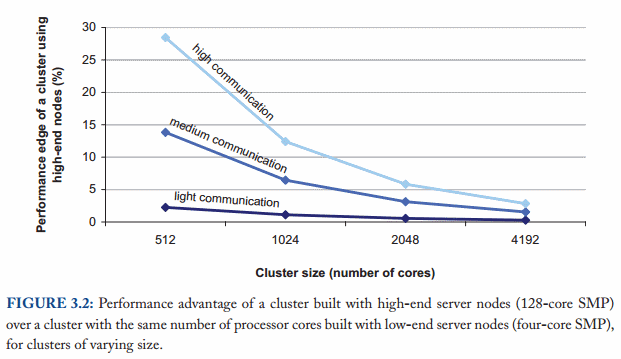
Adding new machines does not linearly increase performance and capacity as in an ideal scenario.
This article focuses on distributed programming in data centers.
Implementation Goals: Scalability and Other Benefits
Scalability
Scalability: The ability of a system, network, or process to handle a growing amount of work, or its potential to be enlarged to accommodate that growth.
- Size scalability
- Geographic scalability
- Administrative scalability
Performance and Latency
Performance: The amount of useful work accomplished by a computer system compared to the time and resources used.
Latency: Essentially the time it takes for new data to appear in the system. In distributed systems, this is constrained by the speed of light and disk speeds, etc.
Availability (Fault Tolerance)
Availability: The proportion of time a system is in a functioning condition. Availability = uptime / (uptime + downtime).
Distributed systems can tolerate partial failures through redundancy.
Fault tolerance: The ability of a system to continue operating in a properly defined manner after the failure of some of its components.
Constraints
Distributed systems are constrained by two physical factors:
- Number of nodes (increases with required storage and computing power)
- Distance between nodes (information travels at most at the speed of light)
Performance and availability are defined externally, usually expressed as SLAs (Service Level Agreements).
Abstractions and Models
Abstractions make things manageable; models precisely describe the key properties of distributed systems.
For example:
- System model (Asynchronous/Synchronous)
- Failure model (Crash failures, Partitions, Byzantine)
- Consistency model (Strong consistency, Eventual consistency)
Design Techniques: Partitioning and Replication
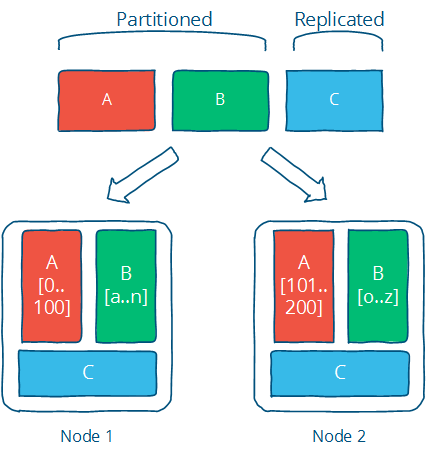
Partitioning
Dividing a large dataset into smaller independent sets.
- Partitioning improves performance by limiting the amount of data to be examined and locating related data in the same partition.
- Partitioning improves availability by allowing partitions to fail independently.
Replication
Copying the same data on multiple machines is the primary way to combat latency.
- Improves performance by adding computing power and bandwidth on new data copies.
- Improves availability by creating additional copies of data.
Replication needs to follow a consistency model.